This post describes a T5-based chess engine that achieves human enthusiast level performance. This model was trained entirely with imitation learning on human expert data from lichess. It does not utilize any form of search: each move is made with a single forward pass of the model.
This will cover:
1. Why chess?
2. Why avoid search?
3. Why sequence-to-sequence?
4. How does the model work?
“If one could devise a successful chess machine, one would seem to have penetrated the core of human intellectual behavior.”
-Newell, Shaw, Simon (1958)
Chess fascinated almost all of the leading figures in early computing. Charles Babbage thought about how to make his analytical engine play chess. Norbert Wiener included a note in Cybernetics about the creation of chess playing machines. Claude Shannon developed the “Shannon Number”, an estimate of the complexity of chess. Alan Turing developed the first “chess engine”, Turbochamp, which so predated easy access to computers that he had to compute the moves by hand with a pencil and paper. There was likely a time when there were more people thinking about applying computing to chess than there were computers.
Chess was considered the “drosophila” of intelligence and reasoning. The Drosophila Melanogaster was a species of fly used to model genetics. It represented the simplest system that contained the basic components needed to study the highest levels of genetics. Chess was thought of the same way: it was the simplest system with the basic components needed to study the highest levels of thought. Chess was regarded as a pure intellectual activity, akin to writing poetry. It was for a time a legitimate question of debate as to whether it was something a computer could even do at the same level as a human. The going assumption was that a series of significant breakthroughs would be needed to get to that point. This is what drove many of those early figures in computing to the problem.
Traditional algorithms rely on searching the game tree to evaluate different positions. What makes chess and other games interesting is that this tree is so large, it is rarely possible to enumerate even a small portion of it. The main focus for much of the research was developing clever ways to perform this search as efficiently as possible. This meant both searching faster and more selectively.
In 1997, Deep Blue became the most famous example of this approach. The IBM developed chess engine was able to defeat the current world chess champion Garry Kasparov, finally ending any question of whether or not computers could play expert level chess. However, Deep Blue fell well short of many of the expectations of what a superhuman chess playing program would lead to. The original goal was always to learn something about intelligence. The resulting system was hyper-specific to chess. The hardware itself was specifically tuned for chess to eek out any last performance gains. Kasparov quipped, “Deep Blue was intelligent the way your programmable alarm clock is intelligent. Not that losing to a $10 million alarm clock made me feel any better.” It was very good at chess to be sure, but it was a far cry from anything resembling how humans played the game.
If all you have is a machine that bests humans by means of speed alone, what really do you have? What have you understood about human intelligence, what core of the human intellect have you penetrated? (“Well,” one Berkeley professor mused, “maybe it turns out humans are fast and not deep after all!”)
-Machines Who Think, Pamela McCorduck (1979)
What we learned from Deep Blue was not some deeper understanding of intelligence, but something more surprising. The missing component was not some breakthrough. The backbone of Deep Blue was alpha-beta search, which had been around since at least the 1950s. The missing component, it turned out, was simply compute. Search with extra bells and whistles was enough to surpass human level performance. All we needed was better tuned heuristics and faster computers. This not surprisingly sucked a bit of the air out of the field as they turned their attention elsewhere.
These methods represented a trade off of performance for relevance. Humans obviously don’t think like Deep Blue played. They do not have access to a perfect simulation of the environment in their head. Any algorithm that requires enumerating thousands or millions of potential outcomes is doing something that fundamentally does not match the human thought process.
Developing AI systems that can play chess was momentarily reinvigorated with Deepmind’s AlphaZero project. At the time, deep reinforcement learning was racking up some impressive accolades. After achieving superhuman level performance in Atari games and more famously Go, the DeepMind team decided to try to try their hand at chess as well. As almost an afterthought, chess was chosen as one of the other games used to demonstrate the generality of the core algorithm they used for Go. The resulting model ended up being able to beat Stockfish, the best traditional chess engine at the time. Here we had for the first time a deep learning based algorithm topping the best of the best “traditional” search-based algorithm.
It was a fantastic achievement, but at the core they were still doing search; just less. Their algorithm was driven by a form of Monte Carlo Tree Search (MCTS). Instead of evaluating 70 million boards per second like Stockfish, they only evaluated around 80 thousand. A big step forward of course, but still more of the same.
It is worth considering what we are missing by relying on search. What does it say if the current state of the art models cannot play chess well without this additional crutch, but humans can? Nowadays you can write a search based heuristic algorithm that can beat competent humans in a hundred lines of code or so on minimal hardware. The idea for this project was to instead try to develop a deep learning based chess engine that was competent at chess (better than the author at the very least) without using any kind of search at all. The network should be able to compute strong moves in a single forward pass. 1
Still, when
they make you write your poems, later on,
who’d envy you, force-fed
on all those variorum
editions of our primitive endeavours
those frozen pemmican language-rations
they’ll cram you with? denied
our luxury of nausea, you
forget nothing, have no dreams.
-Adrienne Rich, excerpt from “Artificial Intelligence”, (1961)
One thing that is particularly underrated about Transformers is their generality in a computational sense. Most people associate them only with NLP since that is where they first gained traction. At a fundamental level, they represent high performance methods for solving sequence-to-sequence problems. These are problems in which we want to learn a mapping one sequence of items to another. Language translation, for example, is generating a sequence of tokens corresponding to a sentence in one language to a sequence of tokens corresponding to the same sentence in another language.

Computationally, you can formulate effectively every single problem that can be represented digitally as sequence-to-sequence problem. Just map the bits representing object A into the bits representing object B. Of course, you won’t make much progress doing so, but what matters here is the expressibility. You can express the problem as a sequence-to-sequence problem and then tune the representation. This is much preferable to the reverse: finding a representation and then trying to tune an architecture to match the computation.
This does not mean transformers can solve any problem. They are still constrained by the limits of computational learning theory. No matter how big your network is, it won’t be able to solve the traveling salesman problem for an arbitrary number of cities in polynomial time. What is important is that it can try.
When it comes to transformers, language models in particular have demonstrated groundbreaking performance across a wide variety of tasks. In turn, they have received larges amount of research and investment. Instead of developing a model from scratch, we can lean on the generality of these models.
Towards this end, you can easily phrase chess as a sequence-to-sequence problem. All you need to do so is to create a tokenized representation for the board and the target move. Instead of come up with our own representation from scratch, we can utilize the pre-existing text based representations. For example, every move in chess can be represented in UCI formatting. This involves specifying the square from which you would like to move the piece, the square to which you would like to move it, and whether or not this is a promotion. You can easily write your own tokenizer for this “language” that maps any UCI move into a series of numeric symbols.

This is not only useful for sequence-to-sequence models, but it also represents a powerful decomposition of the problem. The standard way to represent moves for these deep learning based systems is a categorical distribution over all possible moves. In other words, you create some mapping that labels each unique move with a unique number, and then you learn one distribution over all of these moves. If a move never shows up in your training set, your model will never learn anything about it since the indices are non-interpretable. Meaning that once it has seen move index 365 and move index 243 enough times it can reason about their relationship, but it knows nothing about move index 739 unless it sees that as well. By splitting the move into a small number of sub-moves, the model can more easily reason about different moves and their relationships.
In terms of the representation, we can follow the same process for the board. Each board has a FEN representation, which is a lossless representation of the game state at anytime. Again, this language has a very clean syntax, which makes converting it to a list of numeric symbols very easy. Other methods relied on complex hand engineered features to fit the board state into a CNN. Since we already have textual representations, none of that hand engineering is necessary.

We now have a tokenized representation of the board and a tokenized representation of the moves. Our model will then learn how to generate a distribution over the tokens specifying a move conditioned on the tokens specifying the board. We now only need one more thing to get everything to work: data. The simplest way to get this is just downloading human expert data. Lichess publishes massive amounts of human game data. This data was further parsed into the lichess elite database which only contains games between players with ELO ratings above 2300. A portion of the total months were selected and further downsampled to only include board move pairs coming from players that won. This dataset ended up totaling around a half a billion samples.

T5-base was selected as the underlying model. The encoder-decoder architecture is a more natural choice for this kind of problem, since we have a clear static input and output. 2 We want to be able to attend to the entire board at once, and then generate the parts of the moved with the standard autoregressive attention for generation. It is important to note that there is nothing specific about the T5 model that makes this work. We could have used any off the shelf language translation model and it would have worked just as well. The T5 model is nice because we know google already has done an extensive ablation study on the architecture across different tasks, so we can be somewhat confident its in a good starting spot.
The only modification that made to the architecture besides matching the output dimensions to our vocabulary size is replacing the shared embeddings for the encoder and decoder with a separate embedding for each. This is useful since we have two fundamentally different token types in the input and output. The model was trained from scratch with the standard autoregressive modeling task with teacher forcing on a single epoch of the data. This took around seven days on a TPU.
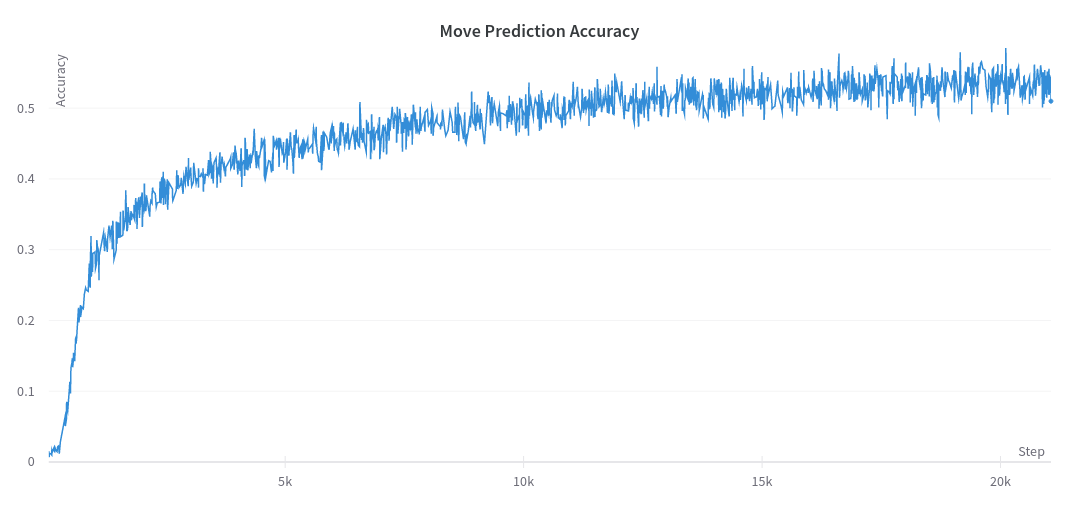
Since our model was effectively doing a form of imitation learning, we can evaluate its ability at imitating our experts. As you can see from the above chart, the model gets fairly good at being able to predict the move the human expert would select. It is important to remember that there are often multiple “correct” moves for every board, and the human experts can frequently disagree. Since it is modeling the action space in a compositional way, there are over 15,000 different moves it can output, almost all of them invalid. Even with all of this, it is able to learn how to find the single right move over half the time.
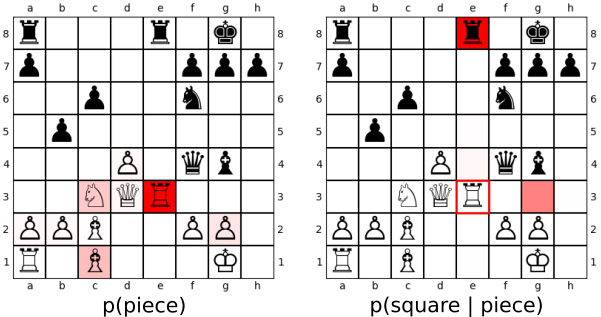
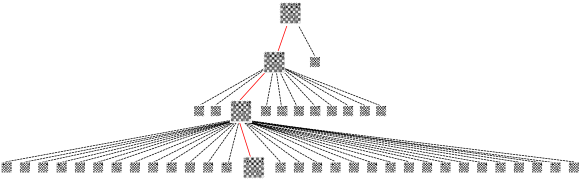
Because of this compositional action space, we can make visualizations at every step. This means we can directly compare what other pieces it was considering, or what other squares it is considering moving pieces too. This is a very useful tool for analysis. It takes all of the potential possible moves and quickly is able to cut them down into the one or two that are worth considering. Notice in the example above the model is effectively only considering two potential locations for the rook out of the 10 total.
But how well does it play? Estimating ELO without playing games against a large pool can be a little tricky. It was able to beat the author (ELO ~900-1200), some friends with ratings between 1000-2000 and Stockfish at depth 2. Automatic estimates put its performance in the 1500-2000 range. An example of this model defeating Stockfish at depth 2 is included below.
In conclusion, this demonstrates a language model based chess engine that achieves playing performance at the level of an enthusiast human solely through imitation learning. It does so without using any kind of explicit search mechanism. The hope is that exploring these kinds of models gets closer to the original goals laid out in the initial explorations of computers and chess.
Special thanks again the to TPURC program, without which this project would not have been possible.
The first attempt at this challenge was around 2018 and focused on deep reinforcement learning. Specifically, DQN trained via a semi-clever board state sampling scheme. The states were generated not via self-play, but via play against a random opponent. To improve exploration, the starting state was randomly sampled by applying N moves before every game. The architecture was pulled directly from computer vision, much like AlphaZero and others. This setup was able to learn to comfortably beat random opponents, but struggled against the simplest opponents.↩
Another work used GPT-3 as the base architecture and finetuned the weights pre-trained on text: https://arxiv.org/abs/2008.04057↩